
CATCG:
Un sistema de análisis morfosintáctico para el catalán
[ català ]
Grupo de Lingüística Computacional
Universitat Pompeu Fabra
Barcelona
CATCG: ARQUITECTURA DEL SISTEMA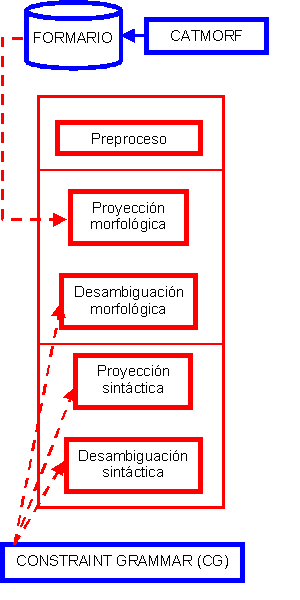
|
CATCG: DESCRIPCIÓN
CATCG es un sistema de análisis morfosintáctico superficial para texto no restringido en catalán. Es de base lingüística (formalismo Constraint Grammar) y altamente modular. Está siendo desarrollado por el grupo GLiCom de la Universitat Pompeu Fabra (Barcelona)
Lo forman los siguientes módulos (ver figura):
- PREPROCESO: verticaliza el texto e identifica oraciones, párrafos, fechas, cifras, nombres propios y abreviaturas.
- PROYECCIÓN MORFOLÓGICA: se realiza sin tener en cuenta el contexto, a partir de la información del FORMARIO:
- El formario (tabla de formas) se construye a partir de CATMORF, un analizador-generador morfológico de dos niveles
- Contiene información de categoría morfológica y rasgos flexivos, así como de subcategorización verbal
- GRAMÁTICAS CG
El núcleo del sistema lo forman tres gramáticas regulares escritas en el formalismo CONSTRAINT GRAMMAR. La estrategia esencial de esta aproximación consiste en elaborar un análisis morfosintáctico parcial a partir de la información contextual proporcionada en cada oración. Las gramáticas realizan las tareas siguientes:
- Desambiguación morfológica: la desambiguación morfológica asigna a cada palabra una etiqueta con información morfológica (p.e., nombre común masculino plural).
Ej. de regla
remove target (verb) if (0 nom) (-1 det) (-2c prep);
- Proyección sintáctica:la proyección sintáctica se realiza de manera controlada, es decir, evitando proyectar lecturas ambiguas en contextos suficientemente seguros.
Ej. de regla:
map (@atr) target (adj) if (-1 vcop) (not *1 nom barrier bar-df or coma);
- Desambiguación sintáctica: el análisis sintáctico superficial proporciona información sobre la función sintáctica de cada palabra: se asigna una etiqueta con el nombre de la función y, en algunos casos, se indica la dirección del núcleo (p. e., se diferencia entre adjuntos nominales de nombre situado a la izquierda o a la derecha).
Ej. de regla:
remove target (@subj) if (0 nom) (-1C prep);
|
CATCG: ESTADO DEL PROYECTO Y PERSPECTIVAS DE FUTURO
Datos técnicos:
- Tamaño del léxico: aprox. 90.000 lemas
- Velocidad de procesamiento: 1800 p/s
- Plataformas: unix, linux
| |
DeMCat |
ASCat |
| Precisión |
0.92 |
0.78 |
| Cobertura |
0.98 |
0.96 |
| F (alpha = 0.5) |
0.95 |
0.87 |
|
- La relativamente baja precisión de CATCG se debe a la voluntad de conseguir un muy bajo porcentaje de error a favor de la cobertura, es decir, elaborar sólo reglas muy fiables.
- Con el formalismo CG, y con esta aproximación, calculamos que el techo está en un 90%-95% de precisión global.
- Algunas de las ambigüedades persistentes se procesarán en módulos posteriores: actualmente se está desarrollando un módulo para tratar adjunción de SSPP.
- Otra de las direcciones de investigación actuales es la de adquirir y explotar información semántica.
|
CATCG: PROYECTOS
CATCG es una herramienta básica que ya se está aplicando en varios proyectos en desarrollo en el seno de GLiCom:
- BANCTRAD: se trata de una interficie de búsqueda para corpus paralelos anotados con información lingüística (lema, categoría morfológica, etc.) y extralingüística (tema, registro, nivel de especialización, etc.). Sus usuarios potenciales son estudiantes de traducción, traductores, lingüistas y otros profesionales de la lengua.
Financiación: Programa d'Innovació Docent, Universitat Pompeu Fabra
Duración: enero 2000-diciembre 2002
Web de BancTrad: https://iac.upf.edu
- PrADo (Preparación Automatizada de Documentos): creación de correctores gramaticales para español y catalán, con énfasis especial en las interferencias entre estas dos lenguas y con el inglés.
Financiación: proyecto TIC2000-1681-C02-01 del MCYT.
Duración: enero 2001-diciembre 2003.
Web de PrADo: http://prado.uab.es
- ALLES (Automatic Long-distance Language Education System): creación de una plataforma de teleenseñanza para la adquisición de competencia lingüística oral y escrita (tanto en la producción como en la comprensión) dirigida a aprendices de segundas lenguas en el ámbito de la economía. Lenguas de trabajo: alemán, inglés, catalán y español.
Financiación: proyecto IST-2001-34246 del
Vth RTD FrameWork Programme de la UE.
Duración: junio 2002-junio 2005.
El Grupo GLiCom
Los objetivos principales de GLiCom son el estudio de los procesos computacionales aplicados al lenguaje, la elaboración de aplicaciones informáticas para el tratamiento computacional del lenguaje natural y la
formación de profesionales en lingüística computacional, traducción automática y, en general, en el procesamiento del lenguaje natural.
Los ámbitos científicos en que se investiga y los campos de aplicación de las herramientas elaboradas por GLiCom son varios: por un lado, se realizan estudios de los cinco niveles tradicionales de
descripción lingüística y, por otro, se investiga en las estrategias computacionales necesarias para simular la competencia humana del lenguaje en máquinas. Con ello, se persigue el desarrollo de aplicaciones orientadas a la traducción automática, la corrección de textos o, por ejemplo, la extracción de información. Con este fin, se combinan estrategias simbólicas y empíricas, puesto que, dado el estado actual del conocimiento, este parece el planteamiento que asegura un rendimiento óptimo de las herramientas.
Todas las actividades del grupo GLiCom tienen un carácter claramente interdisciplinario (especialmente entre la lingüística y la informática). En GLiCom se considera indispensable una dedicación equilibrada a la investigación básica y a la investigación aplicada, a fin de que ambas puedan retroalimentarse.
GLiCom
Departamento de Traducción y Filología
Universitat Pompeu Fabra
Rambla, 30-32
08002 Barcelona
Persona de contacto: Toni Badia
Tel. 93 542 24 14
Fax 93 542 16 17
http://www.upf.edu/glicom